实时ETL同步任务根据来源Hologres表结构对目标Kafka的topic进行初始化,将Hologres数据实时同步至Kafka以供消费。本文为您介绍如何创建Hologres实时ETL同步到Kafka任务。
使用限制
Kafka的版本需在0.10.2至3.6.0之间。
Hologres的版本要求必须为2.1及以上。
不支持Hologres分区表的增量同步。
不支持Hologres表DDL变更消息同步。
Hologres增量同步支持的数据类型包括:INTEGER、BIGINT、TEXT、CHAR(n)、VARCHAR(n)、REAL、JSON、SERIAL、OID、INT4[]、INT8[]、FLOAT8[]、BOOLEAN[]、TEXT[]、JSONB。
必须使用Serverless资源组,具体操作请参考新增和使用Serverless资源组。
添加数据源
新建Hologres数据源
获取Hologres数据源信息。
进入Hologres控制台。单击左侧导航栏的实例列表进入实例列表页面,找到您要进行数据同步的Hologres实例。单击实例名,进入实例详情界面获取到Hologres的实例ID、地域信息、数据源地址。如果Hologres开通了指定VPC的网络链接,则可以获取到VPC ID、Vswitch ID。
手动添加Hologres数据源。
详情请参见创建Hologres数据源。
新建Kafka数据源
您可以手动添加Kafka数据源至DataWorks,详情请参见:Kafka数据源。
准备Serverless资源组并与数据源网络连通
Hologres实时ETL同步到Kafka集成任务依赖于Serverless资源组,需要在资源组列表页面新建资源组创建新版资源组。具体操作请参考新增和使用Serverless资源组。
在进行数据同步之前,需要确保您的资源组和数据源之间的网络连接正常。具体操作请参考网络连通方案。
Kafka与Hologres支持的网络类型如下:
Kafka:指定VPC网络、公网。
Hologres:指定VPC网络、通用VPC网络(AnyTunnel)、公网。
若您的新版资源组和数据源属于同一地域,可以使用地域VPC内网(AnyTunnel或者SingleTunnel)连通资源组和数据源。如果是SingleTunnel网络类型实现网络连通性需要执行:
在DataWorks侧对Hologres实时ETL同步到Kafka所需的通用型资源组进行来新增绑定专有网络。
点击Hologres实时ETL同步到Kafka对应资源组上的网络设置,可以获取到已绑定的专有网络的交换机网段IP,将交换机网段IP填写在Hologres数据源和Kafka数据源对应的数据库白名单中。
若您的资源组和数据库位于不同的地域,您可以通过以下操作实现公网连通。
为资源组绑定专有网络VPC和交换机配置公网NAT网关。具体操作请参见使用公网NAT网关SNAT功能访问互联网。
在数据库侧添加VPC-NAT网关的公网地址IP至白名单中。
创建同步任务
进入数据集成主站,单击同步任务进入同步任务页面,在页面的创建同步任务模块来源处下拉选择Hologres,去向处下拉选择Kafka后,单击开始创建,进入新建同步任务页面。
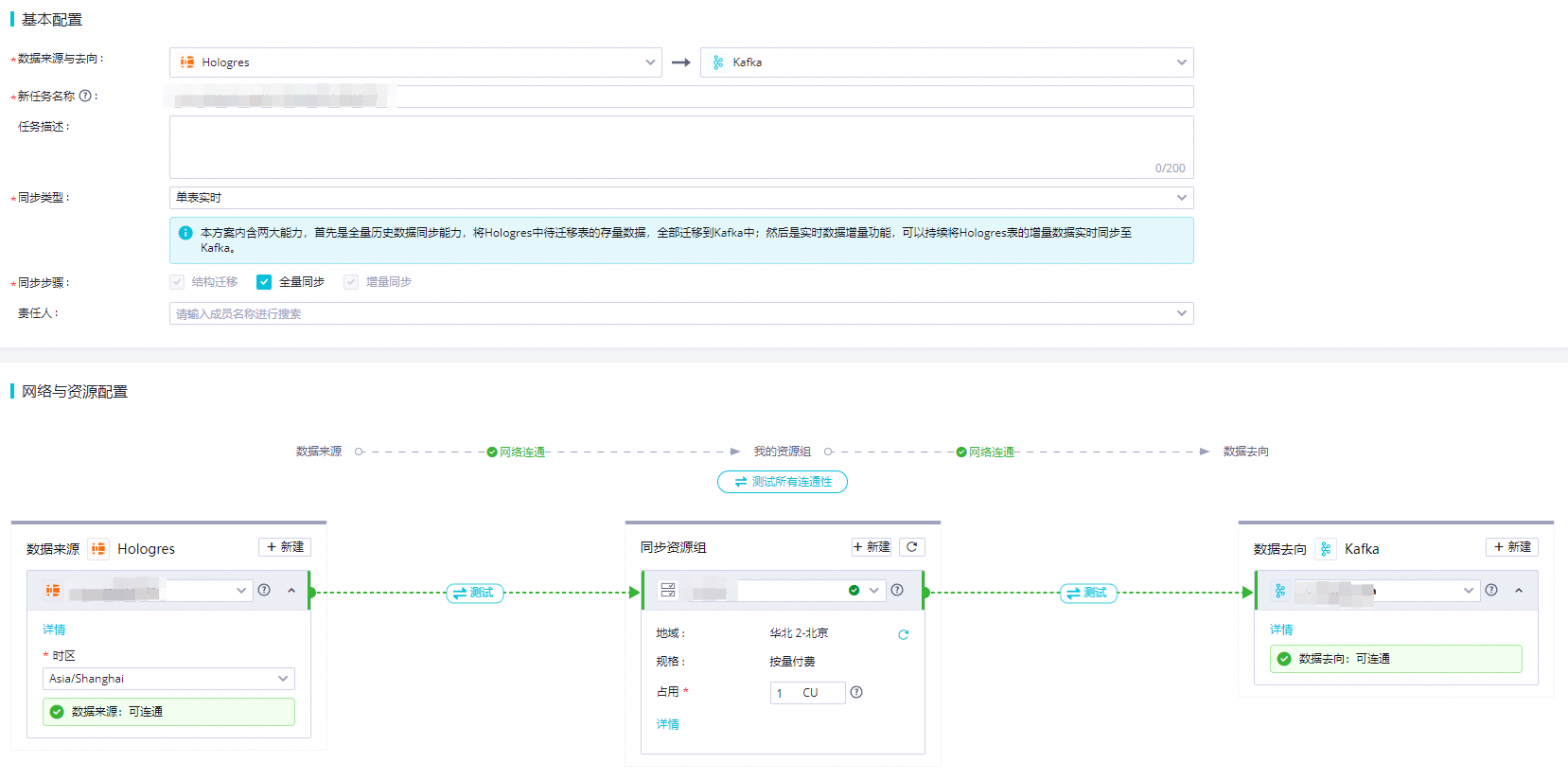
配置同步任务基本信息。
数据来源与去向:来源选择Hologres,去向选择Kafka。
任务名称:会默认生成一个任务名,可自定义。
同步类型:选择单表实时。
网络与资源配置:配置集成任务具体的数据源、资源组,需要保证数据源与资源组之间的网络连通。
数据来源:下拉选择创建的Hologres数据源。
同步资源组:选择可连通的资源组。
数据去向:下拉选中创建的Kafka数据源。
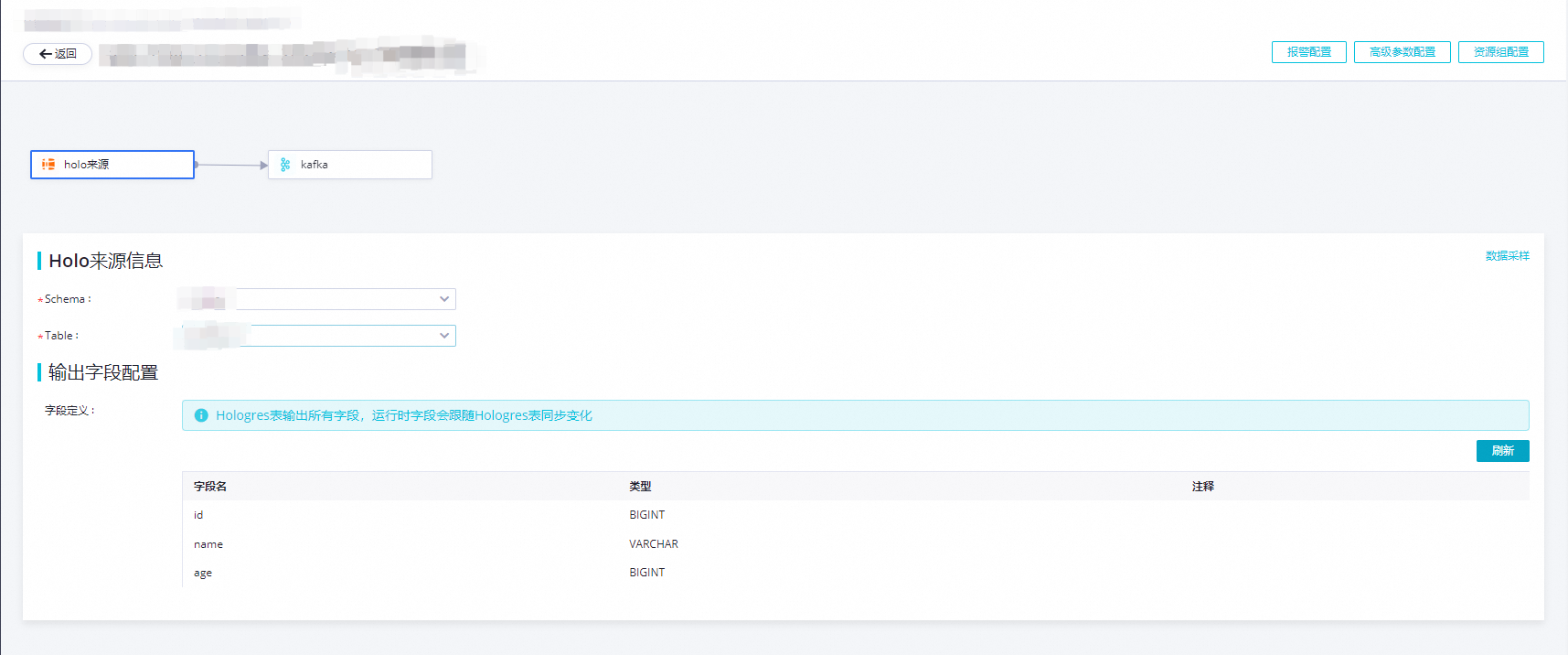
配置Hologres来源信息。
Schema:填写需要同步的表所在的Schema。
Table:填写需要同步的表名。
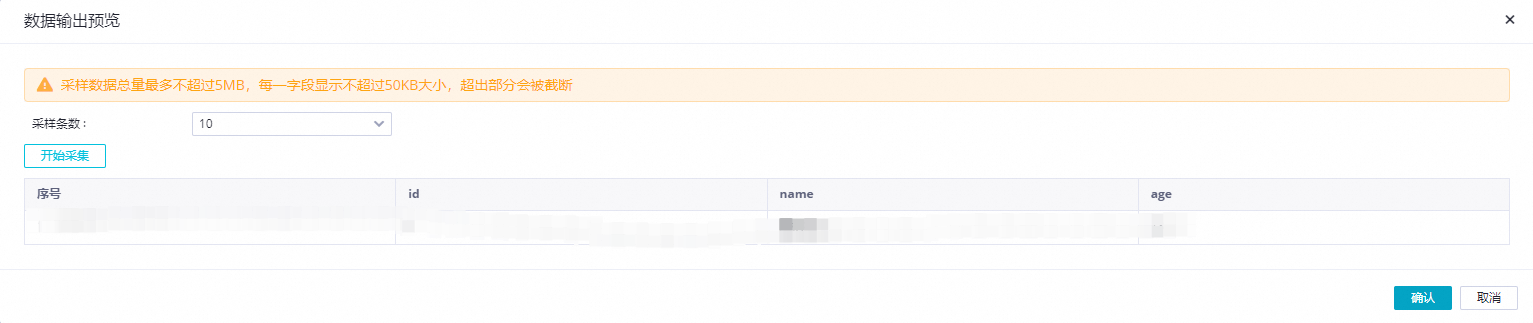
数据采样:点击开始采集后可以对指定Hologres表中已有数据进行采样,预览表中的数据。
编辑数据处理节点。
单击Hologres组件与Kafka组件之间的连接线,可以增加数据处理方式。目前提供5种数据处理方式,您可以根据需要做顺序编排,在任务运行时会按照编排的数据处理先后顺序执行数据处理。五种数据处理方式分别是:数据脱敏、字符串替换、数据过滤、JSON解析和字段编辑与赋值。
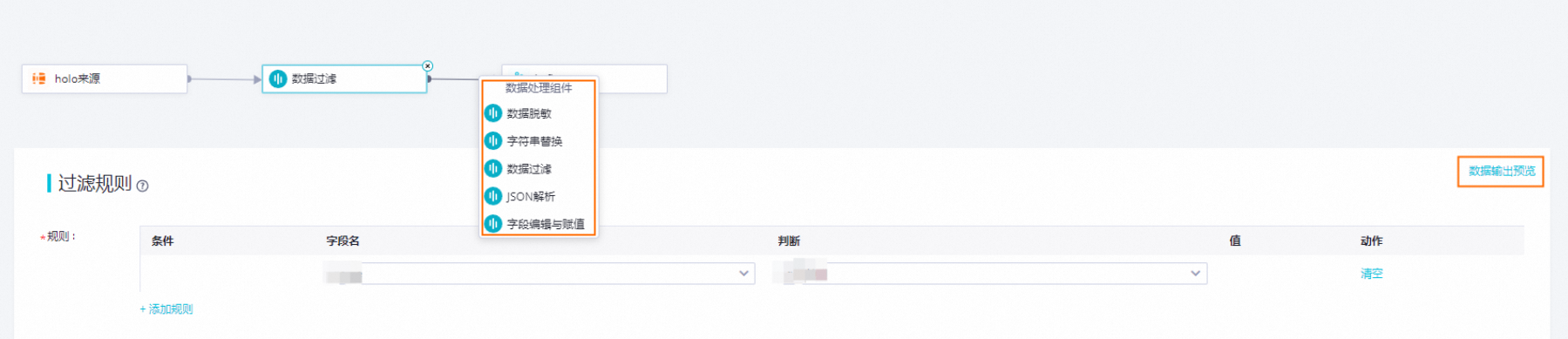
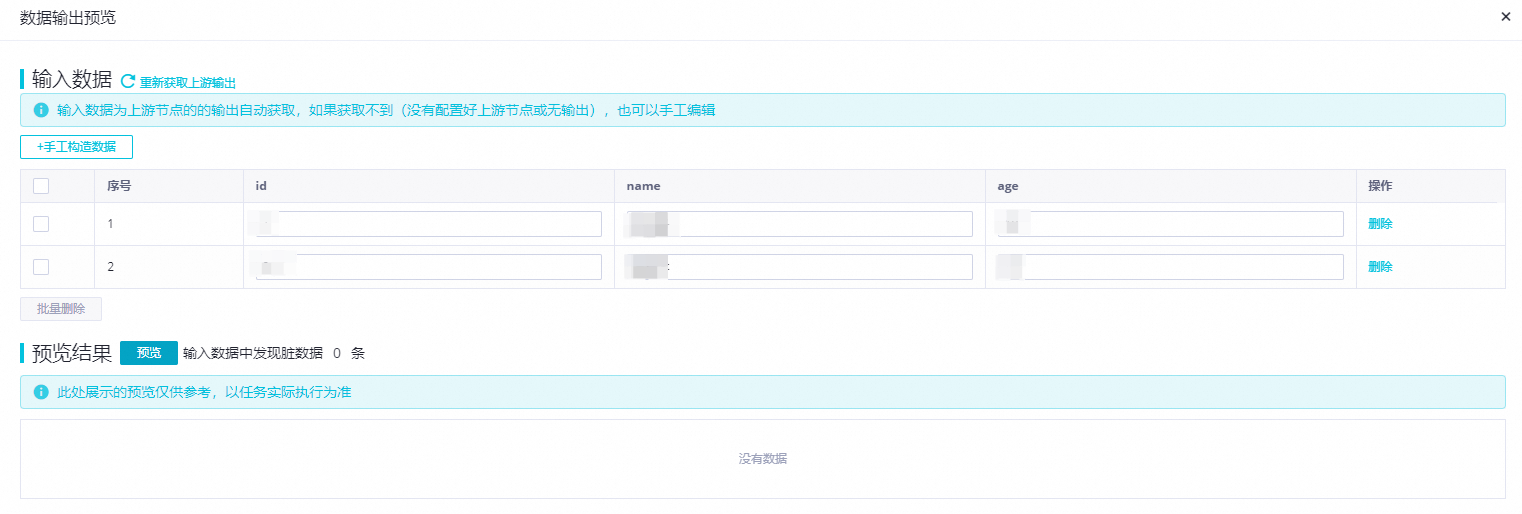
每完成一个数据处理组件配置,可以单击右上角的数据输出预览按钮,在弹出对话框中,点击重新获取上游输出,模拟得到Hologres采样数据经过当前数据处理节点处理后的结果。
在数据输出预览窗口中,您可以根据需要修改输入数据,或者点击手工构造数据按钮自定义输入数据,然后单击预览按钮,查看当前数据处理节点对数据的处理结果,当数据处理节点处理异常,或者产生脏数据时,也会实时反馈异常信息,能够帮助您快速评估数据处理节点配置的正确性,以及是否能得到预期结果。
说明数据输出预览强依赖Hologres来源的数据采样,在执行数据输出预览前需要先在Hologres来源表单中完成数据采样。
配置Kafka去向信息。
主题:Kafka实例中配置的Kafka Topic。
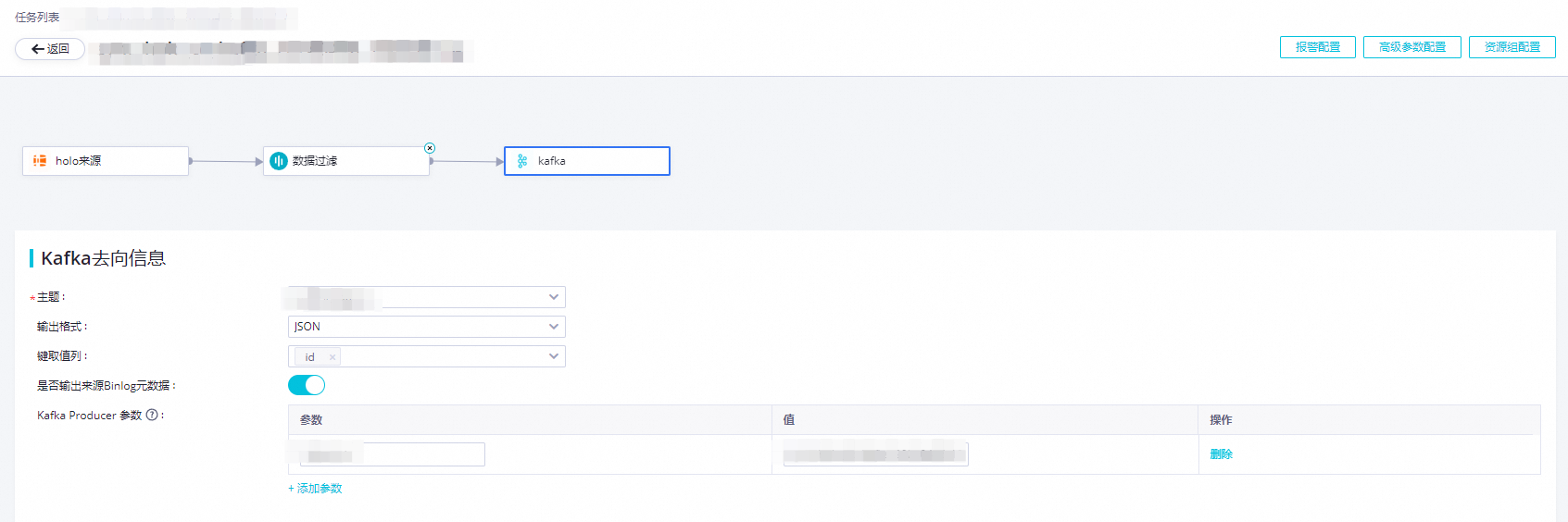
输出格式:确认写入Kafka记录的Value内容格式,支持两种格式:Canal CDC和JSON。
Canal CDC:是Alibaba Canal定义的一种CDC数据格式。
JSON:是将Hologres Binlog中的变更记录,以列表名作为Key,将列表的数据内容序列化为字符串后作为value,组装为JSON格式字符串写入Kafka Topic中。
Hologres中字段类型序列化说明
Hologres字段类型
写入Kafka序列化结果
bit
不支持,任务启动报错。
inet
不支持,任务启动报错。
interval
不支持,任务启动报错。
money
不支持,任务启动报错。
oid
不支持,任务启动报错。
timetz
不支持,任务启动报错。
uuid
不支持,任务启动报错。
varbit
不支持,任务启动报错。
jsonb
不支持,数据写入后报错binlog解析错误。
bigint
数字字符串:"2"。
decimal(38,18)
小数位数跟精度定义一致的数字字符串,"1.234560000000000000"。
decimal(38,0)
小数位数跟精度定义一致的数字字符串,"2"。
boolean
"true"/"false"。
date
yyyy-MM-dd格式日期字符串:"2024-02-02"。
float4/float8/double
数值字符串,转换后与Holo查询结果一致,不会补零:"1.24"。
interger/smallint
数字字符串:"2"。
json
json字符串:"{\"a\":2}"。
text/varchar
utf8编码字符串:"text"。
timestamp
精确到微秒的时间字符串
如果毫秒部分和微秒部分为0,写入时会省略小数点后的0,例如:
"2020-01-01 09:01:01.000000"写入后为"2020-01-01 09:01:01"。
如果微秒部分为0,写入时会省略毫秒后面的0,例如:
"2020-01-01 09:01:01.123000"写入后为"2020-01-01 09:01:01.123"。
如果微秒部分不为0,会在最后补3个0,例如:
"2020-01-01 09:01:01.123457"写入后为"2020-01-01 09:01:01.123457000"。
timestamp with time zone
精确到毫秒的时间字符串:"2020-01-01 09:01:01.123"。
如果毫秒部分为0,写入时会省略小数点后的0,例如:
"2020-01-01 09:01:01.000"写入时为"2020-01-01 09:01:01"。
bigserial
数字字符串:"2"。
bytea
base64编码字符串:"ASDB=="。
char
定长字符串:"char"。
serial
数字字符串:"2"
time
精确到微秒时间字符串。
如果毫秒部分和微秒部分为0,写入时会省略小数点后的0:
例如"2020-01-01 09:01:01.000000"写入后为"2020-01-01 09:01:01"。
如果毫秒部分或微秒部分不为0,会在最后补充0到纳秒位:
例如"2020-01-01 09:01:01.123457"写入后为"2020-01-01 09:01:01.123457000"。
int4[]/int8[]
字符串数组:["1","2","3","4"]。
float4[]/float8[]
字符串数组:["1.23","2.34"]。
boolean[]
字符串数组:["true","false"]。
text[]
字符串数组:["a","b"]。
说明注意时间类型的字段在序列化时,若不在[0001-01-01,9999-12-31]范围内的数据,序列化结果与Hologres中的查询结果会有差异。
元数据字段内容说明
说明与Canal CDC格式一样,Hologres Binlog三种类型变更记录插入、更新和删除中,一次更新会生成两条JSON格式记录写入Kafka Topic中,一条对应更新前的数据内容,一条对应更新后的数据内容。
JSON格式可以选择是否输出来源Binlog元数据,如果勾选,在JSON格式字符串中会加入一些描述Hologres Binlog变更记录属性的字段。

字段名
字段值含义
_sequence_id_
Hologres Binlog中记录的唯一标识,对于全量同步数据填充null。
_operation_type_
DML变更类型,可选值为"I"/"U"/"D",对应插入、更新和删除,对于全量同步数据填充"I"。
_execute_time_
13位毫秒时间戳。
对应Hologres表对应的数据变更发生时间。
对于全量同步数据填充0。
_before_image_
增量同步的消息数据是否对应变更前内容,Y-是,N-否。
全量同步填充N。
消息变更类型为插入时填充N。
消息变更类型为更新时,会往Kafka写入两条记录,一条记录填充Y,一条记录填充N。
消息变更类型为删除时填充Y。
_after_image_
增量同步的消息数据是否对应变更后内容,Y-是,N-否。
全量同步填充Y。
消息变更类型为插入时填充Y。
消息变更类型为更新时,会往Kafka写入两条记录,一条记录填充Y,一条记录填充N。
消息变更类型为删除时填充N。
键取值列:选取的是源端列,对应列值会序列化为字符串后,用逗号拼接作为写入Kafka Topic中记录的key。
说明列值序列化规则与JSON中的Hologres中列类型序列化规则说明一致。
Kafka Topic中记录的Key值决定写入的分区,相同Key值写入同一分区,为了保证下游消费Kafka Topic时数据能够保持顺序,建议选择Hologres表主键作为键取值列。
如果不选择任何源侧列作为键取值列,Kafka Topic 中记录的Key值为null,会导致Kafka写入分区呈随机写入。
Kafka Producer 参数:是影响写入一致性、稳定性和异常处理行为的参数,一般情况默认配置即可,如有定制化需求可以指定特定参数,各个Kafka集群版本支持的Producer参数可参考Kafka官方文档。
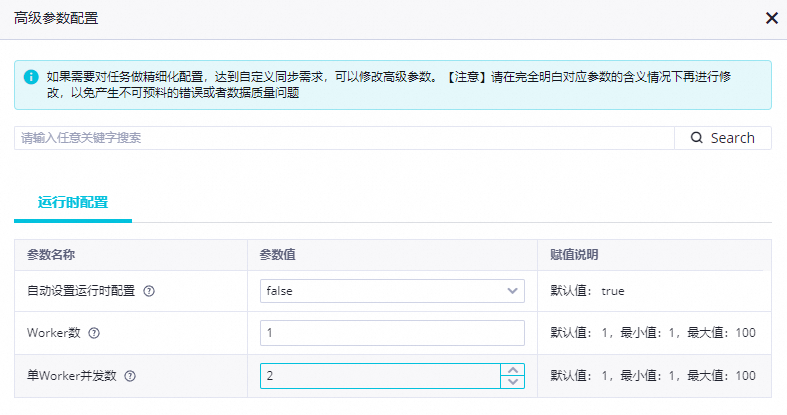
配置高级参数。
点击页面右上角的高级参数配置,对同步任务运行时的并行度和资源进行配置,默认情况下,任务并行度会根据在基本信息配置中指定的CU数自动调整,如果自动调整结果未达到性能预期,可以手动调整。

参数名
说明
自动设置运行时配置
默认值为true,任务并行度会根据在基本信息配置中指定的CU数自动调整,如需手动调整并行度需要选择false。
Worker数
任务运行时启动的子进程个数,不能大于CU数,并且建议(CU数 / 进程数)不要大于10CU,否则可能导致进程无法启动或需要较长时间启动。
单Worker并发数
任务运行时单个进程包含的读写线程数,(Worker数 * 单Worker并发数)不能大于Hologres表的shard数。
配置报警。
为了能够及时感知到同步任务异常并作出相应处理,您可以对同步任务设置不同的报警策略。
单击右上角的报警配置,进入同步子任务报警设置页面。
单击新增报警,配置报警规则,报警规则设置可以参考实时同步任务告警设置最佳实践。
管理报警规则,对已创建的报警规则,您可以通过报警开关控制报警规则是否开启,还可以根据不同报警级别向不同人员发送报警。


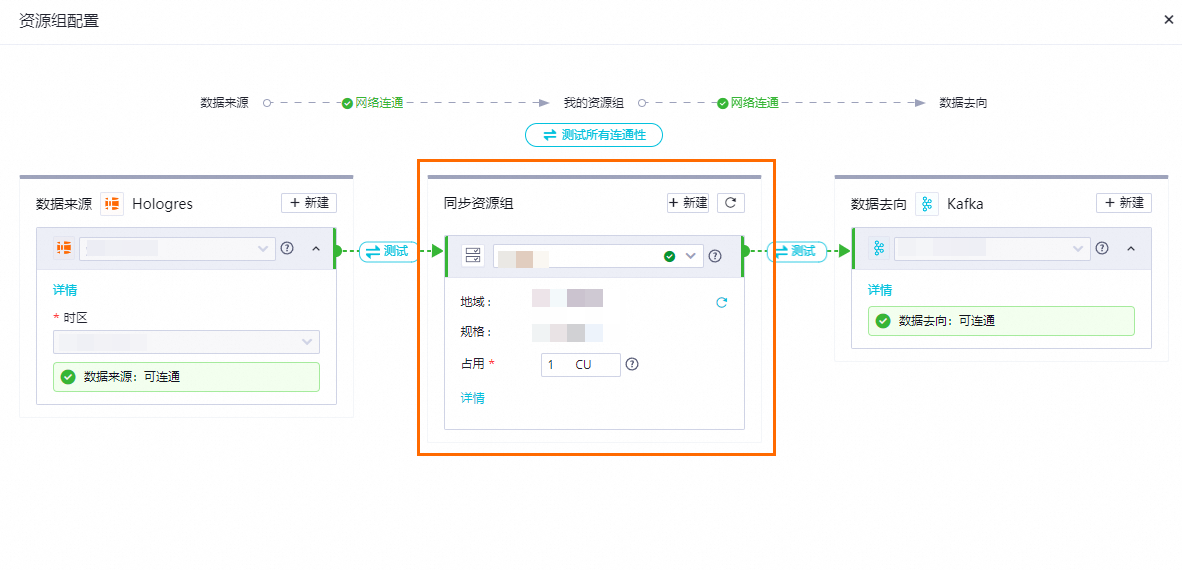
资源组配置。
您可以单击右上角的资源组配置处修改任务运行使用的同步资源组,此处必须保证同步资源组网络与数据来源、数据去向的数据源网络连通性正常,且资源组归属于该工作空间。
任务运维
启动同步任务
配置完成后,界面将自动跳转至任务列表页面,您可单击相应任务操作列的启动来启动任务。

停止同步任务
在启动集成任务后,任务列表页面将显示任务状态为运行中。您可以单击相应任务操作列中的停止来停止任务。
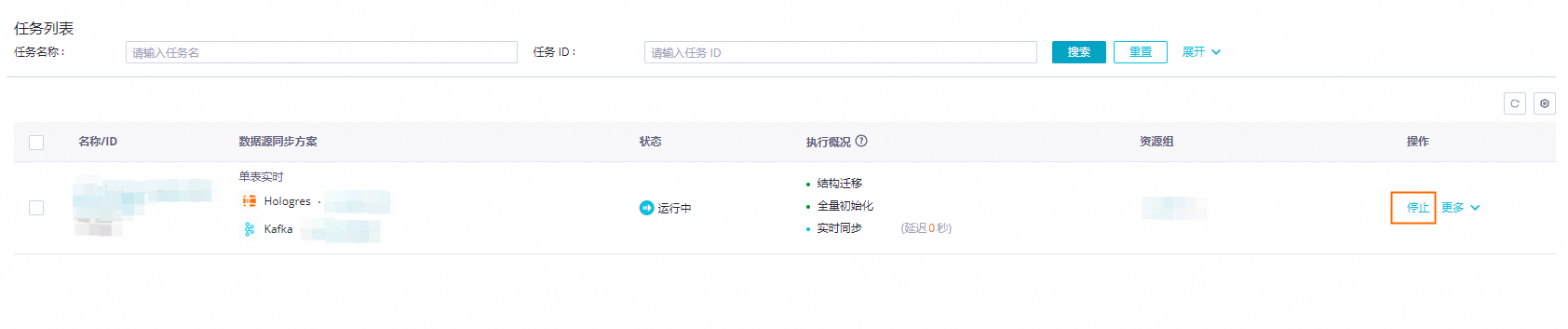
查看任务运行状态
在创建完同步任务之后,您可以在同步任务页面找到已创建的同步任务。只需单击任务名称或执行概况空白处,即可跳转到任务运行详情。

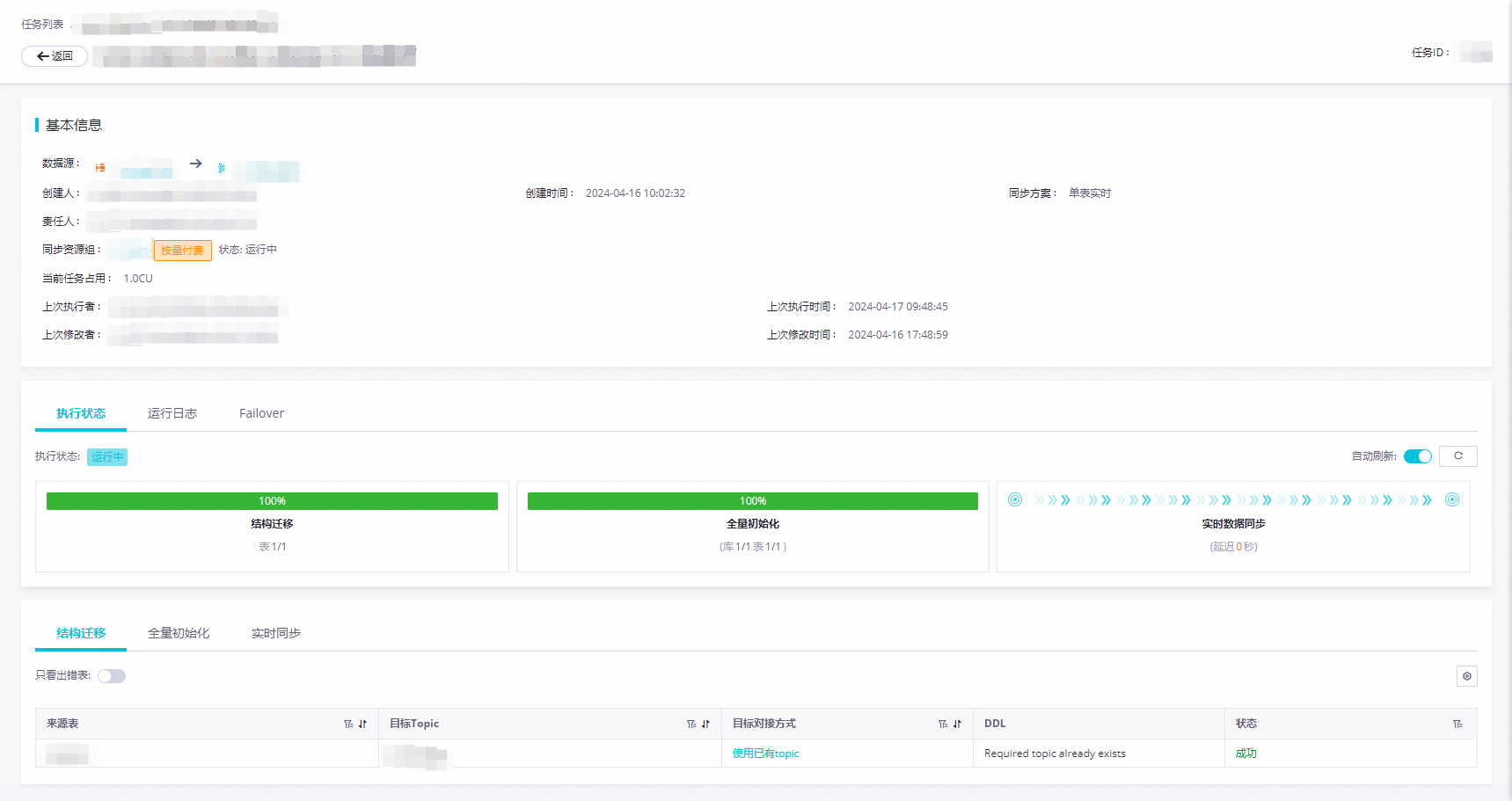
查看任务运行详情。任务详情包括三个部分:
基本信息:包含同步任务的数据源信息、绑定的资源组以及同步任务。
全局信息:包含执行状态、运行日志以及Failover统计。
执行状态:Hologres到Kafka的单表实时任务分为结构迁移、全量初始化、实时同步三个步骤。
运行日志:展示运行时的详细日志。
Failover:展示任务一段时间内的Failover信息。
详细信息:包含结构迁移、全量初始化、实时同步三个步骤的详细信息。
结构迁移:目标表的创建方式(已有表/自动建表),如果是自建表,则会有DDL展示。
全量初始化:全量同步的统计信息,包含进度、同步数据量、同步开始和结束时间。
实时同步:实时同步的统计信息,包含实时的读写流量和报警记录。
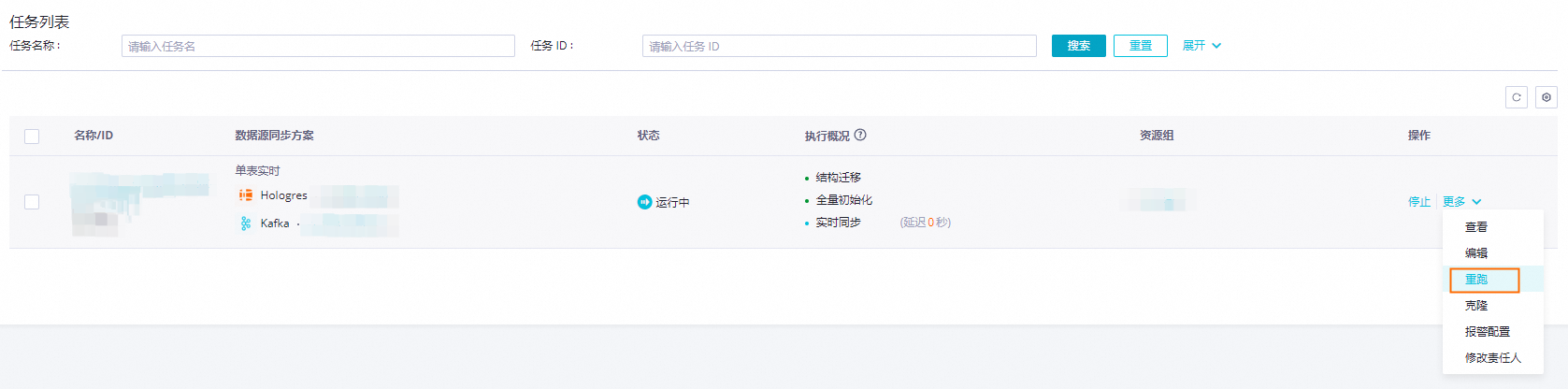
任务重跑
直接重跑。
不修改任务配置的情况下,在任务列表页面的操作列,点击更多按钮,然后直接选择重跑即可。
效果:任务重新运行一次,从结构迁移到启动实时同步的流程。
修改后重跑。
编辑任务后,任务列表页面的操作列将出现应用更新按钮。点击该按钮将直接触发已修改的任务重新运行。
效果:任务按照修改后的任务配置重新运行
